
우리에게 처리해야 할 작업들이 있다고 해 보겠습니다. 다만 작업들은 처음부터 주어지지 않고 시간이 흐르면서 하나씩 도착합니다. 작업을 처리하기 위해 우리는 최대 하나의 작업을 할당받을 수 있는 기계를 몇 대 갖고 있습니다. 문제는 각 작업마다 해당 작업을 처리할 수 있는 기계가 따로 정해져 있다는 것이며, 심지어 어느 기계에서 처리될 수 있는지는 해당 작업이 도착해야 알 수 있다는 점입니다. 우리는 매번 작업이 도착할 때마다 이 작업을 어떤 기계에 할당할지, 그리고 만약 할당한다면, 어느 가용한 기계에 할당하여 줄지를 바로 결정하여야 합니다. 여기서 어려운 점은 이 결정을 후일 번복할 수 없다는 것입니다. 이런 환경에서 작업이 모두 도착했을 때 최대한 많은 작업을 처리하는 것이 목표입니다. 이는 유명한 온라인 최적화 문제 중 하나인 온라인 이분 매칭 문제(online bipartite matching problem)를 나타낸 것으로, 그동안 저는 제 블로그에서 여러 번 이 문제를 다룬 바 있습니다.
그런데 만약 작업을 쪼개어 여러 기계에 할당할 수 있다면 어떻게 될까요? 예를 들어, 어떤 작업이 도착했을 때, 0.2 조각은 첫 번째 기계에, 0.3 조각은 두 번째 기계, 나머지 0.5 조각은 세 번째 기계에 나누어 할당할 수 있는 것입니다. 또한 각 기계는 할당 받은 작업 조각들의 합이 1을 넘지만 않으면 되는 것이고요. 작업을 조각내는 것이 찜찜하다면, 한 작업이 만 개의 동일한 세부 작업으로 이루어져 있고, 각 기계도 최대 만 개의 세부 작업을 할당 받을 수 있는 상황으로 보셔도 무방합니다. 이 문제를 우리는 온라인 분수 이분 매칭 문제(online fractional bipartite matching problem)라고 부릅니다. 구분을 위해 작업을 쪼갤 수 없는 원래 문제는 온라인 정수 이분 매칭 문제(online integral bipartite matching problem)라고도 부릅니다.
지난 포스트에서 우리는 온라인 정수 이분 매칭 문제를 해결하는 경쟁 알고리즘들을 공부하였습니다. 특히, 1/2의 경쟁비를 갖는 결정론적 알고리즘과
문제 정의
문제의 입력은 어떤 이분 그래프(bipartite graph)
어떤 작업
이를 선형 계획법으로 나타내면 아래와 같습니다.
이 LP를 활용하여 문제를 다시 이해해 보겠습니다. 처음에는 알려진 정점이 없고, 각 기계에 가해진 첫 번째 제약 조건만 존재합니다. 매 시각 어떤 작업
물 채우기 알고리즘(water-filling algorithm)
이제 알고리즘을 생각해 보겠습니다. 작업을 쪼갤 수 있기 때문에 가장 쉽게 생각할 수 있는 알고리즘은 역시 균등하게 쪼개서 기계에 할당해 주는 방법이겠습니다. 다시 말해, 작업
온라인 이분 매칭 (Online Bipartite Matching)
어떤 그래프에서 서로 정점을 공유하지 않는 간선의 부분집합을 우리는 매칭(matching)이라고 부릅니다. 매칭의 모양을 살펴보면, 각 정점이 최대 하나의 다른 정점과 짝지어진 꼴입니다. 이를 통
gazelle-and-cs.tistory.com
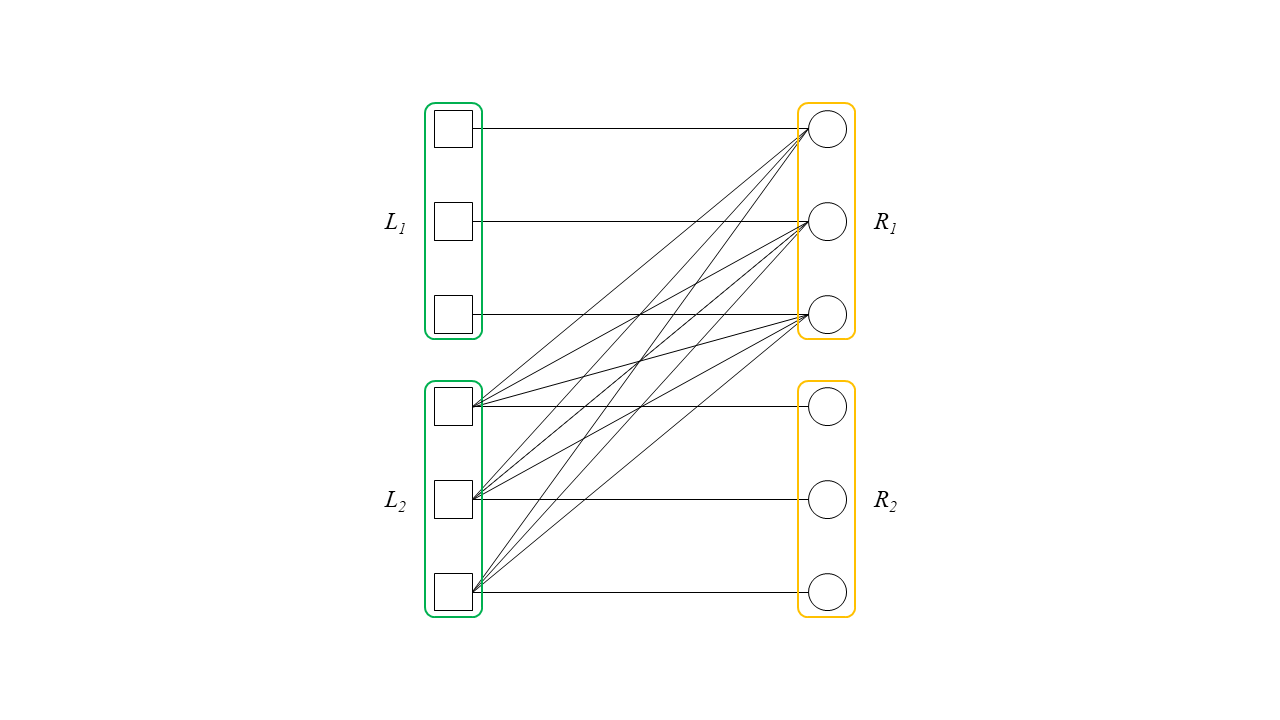
이러한 상황이 발생한 원인은 무엇일까요? 바로
따라서 작업을 할당하는 보다 자연스러운 방법은 부하가 적은 기계부터 차곡차곡 작업 조각을 할당하여 인접한 기계들이 최대한 동일한 부하를 받도록 하는 것이겠습니다. 어떻게 하면 이 목표를 달성할 수 있을지 예시와 함께 알아 보겠습니다. 어떤 작업이 하나 도착했을 때를 생각해 봅시다. 이 작업이 할당될 수 있는 기계들의 그동안 할당 받은 작업량이 다음 그림과 같이 주어졌다고 해 보겠습니다.
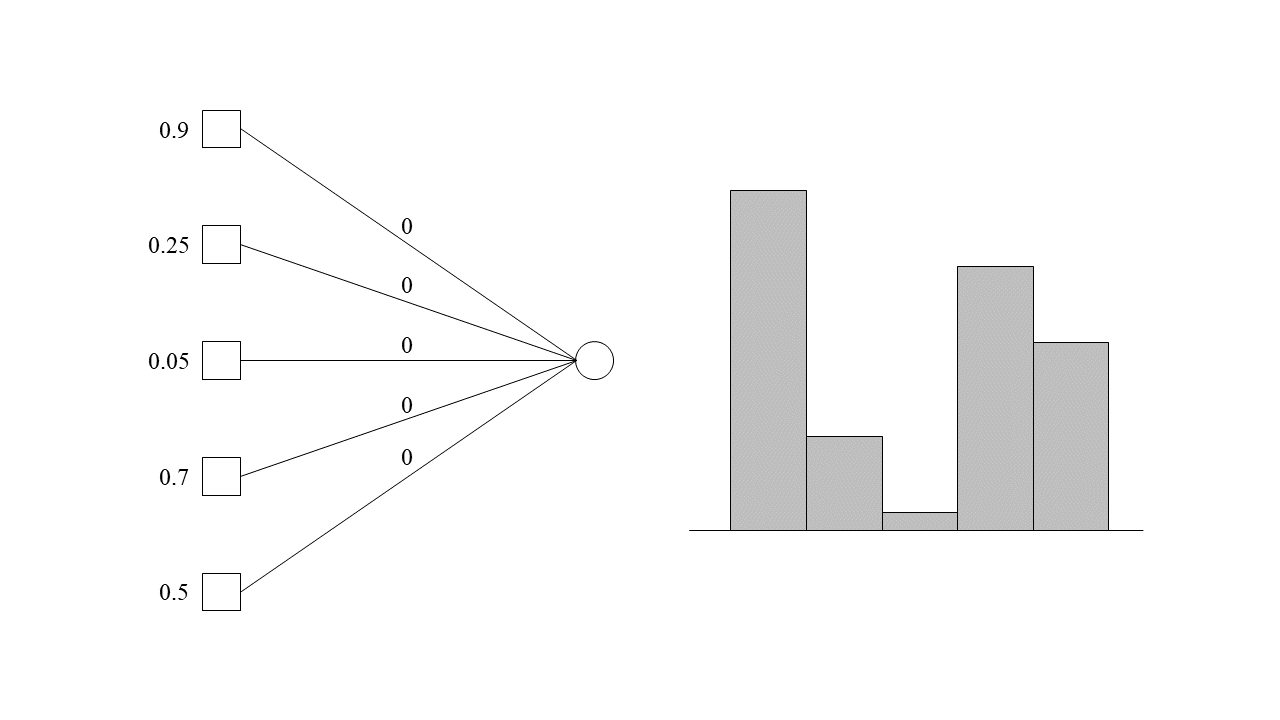
우리의 목표는 인접한 기계들이 최대한 동일한 부하를 받도록 작업을 할당하는 것입니다. 이를 위해 가장 부하가 적은 기계부터 차츰차츰 작업을 할당시켜 보도록 하겠습니다. 현재 세 번째 기계가 가장 적은 0.05의 작업을 받은 상태이므로 세 번째 기계에다가 작업을 할당해 봅시다. 만약 0.1 조각만큼을 할당한다면 아래와 같은 모습이 될 것입니다.
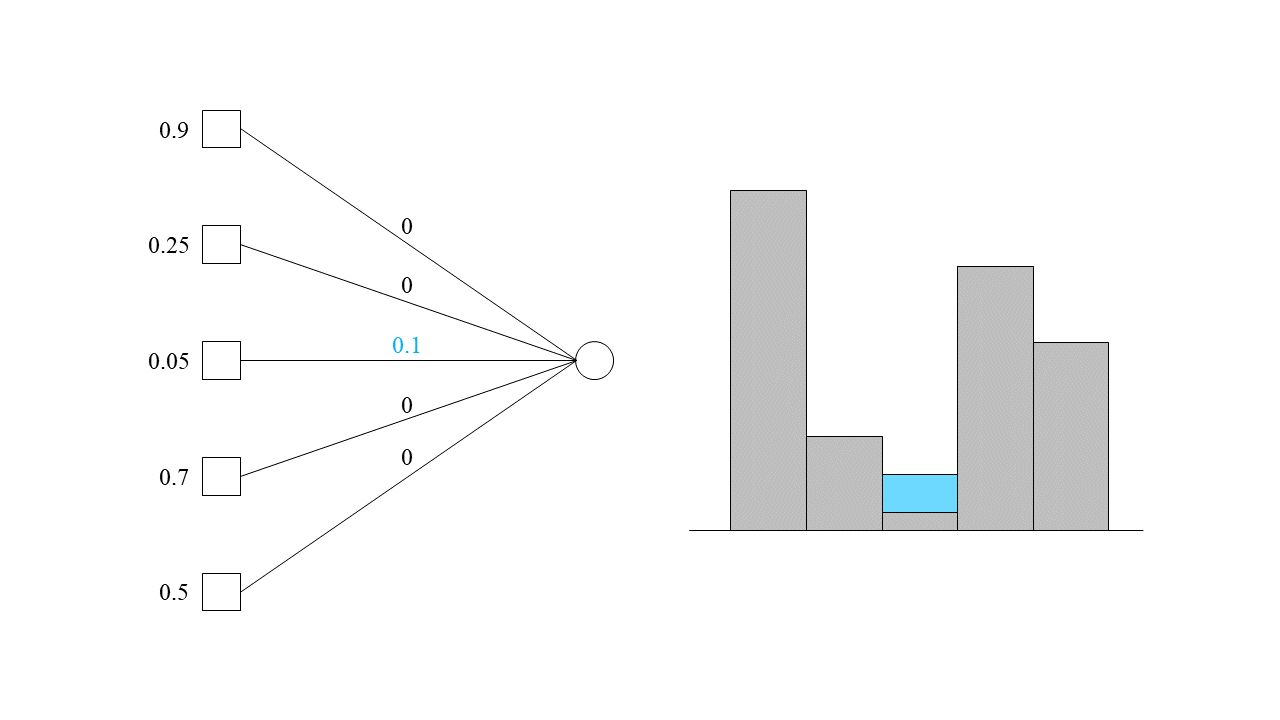
여전히 세 번째 기계가 가장 적은 부하를 받고 있으므로, 세 번째 기계에 계속해서 작업을 할당시켜 보겠습니다. 도합 0.2의 조각이 세 번째 기계에 할당되었을 때를 생각해 보겠습니다.
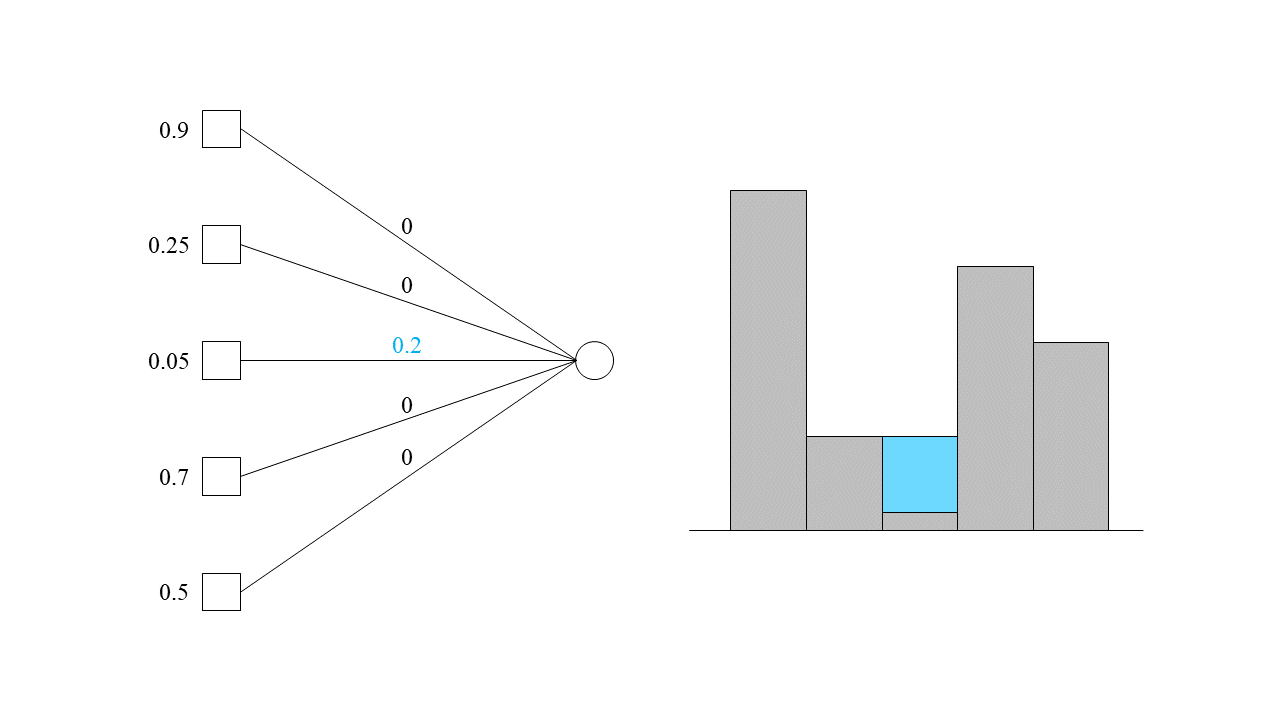
이제 세 번째 기계의 부하가 0.25가 되어 두 번째 기계가 받는 부하와 동일해졌습니다. 여전히 우리는 0.8의 작업 조각이 남아있습니다. 이제부터는 어떻게 작업을 할당해 주는 것이 바람직할까요? 두 번째와 세 번째 기계에 동시에 할당하는 것이 자연스러운 선택일 것입니다. 예를 들어, 이때로부터 두 번째와 세 번째 기계에 0.1씩을 더 할당해 준다면 아래와 같은 모습일 것입니다.
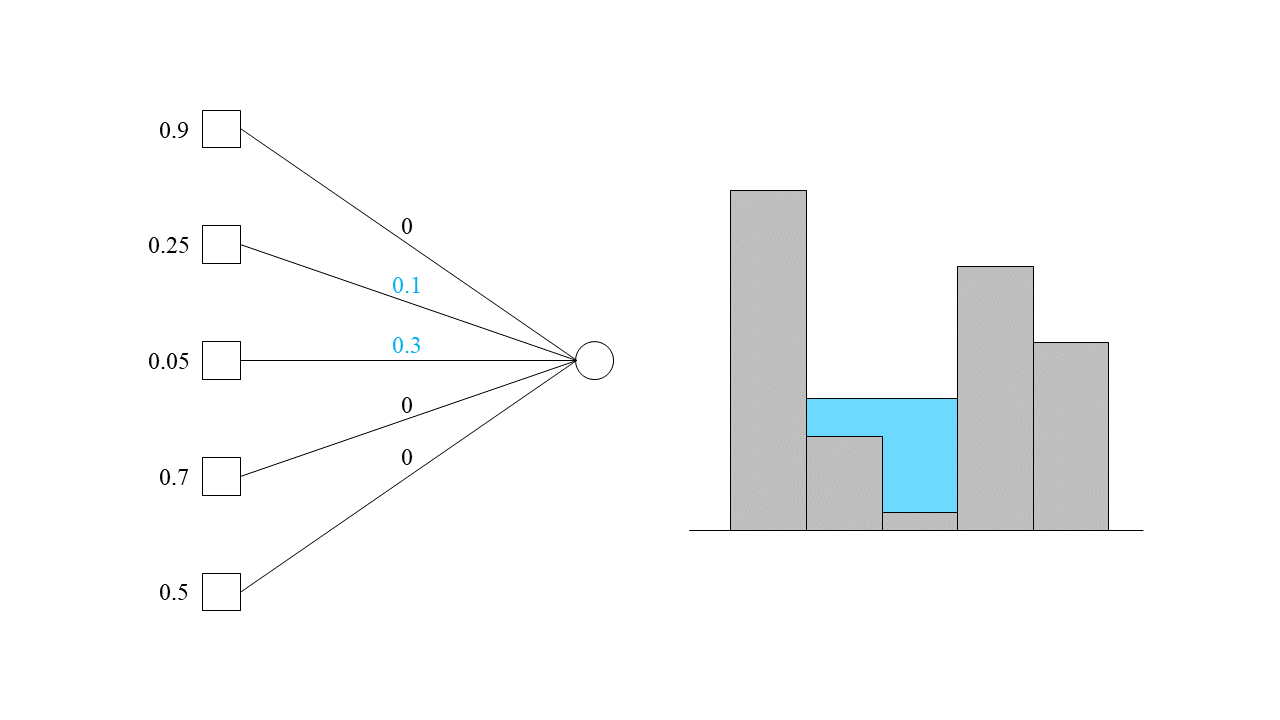
같은 이치로 두 번째와 세 번째 기계에 작업을 할당시키다 보면 언젠가 총 부하가 다섯 번째 기계와 동일해지는 때가 옵니다.
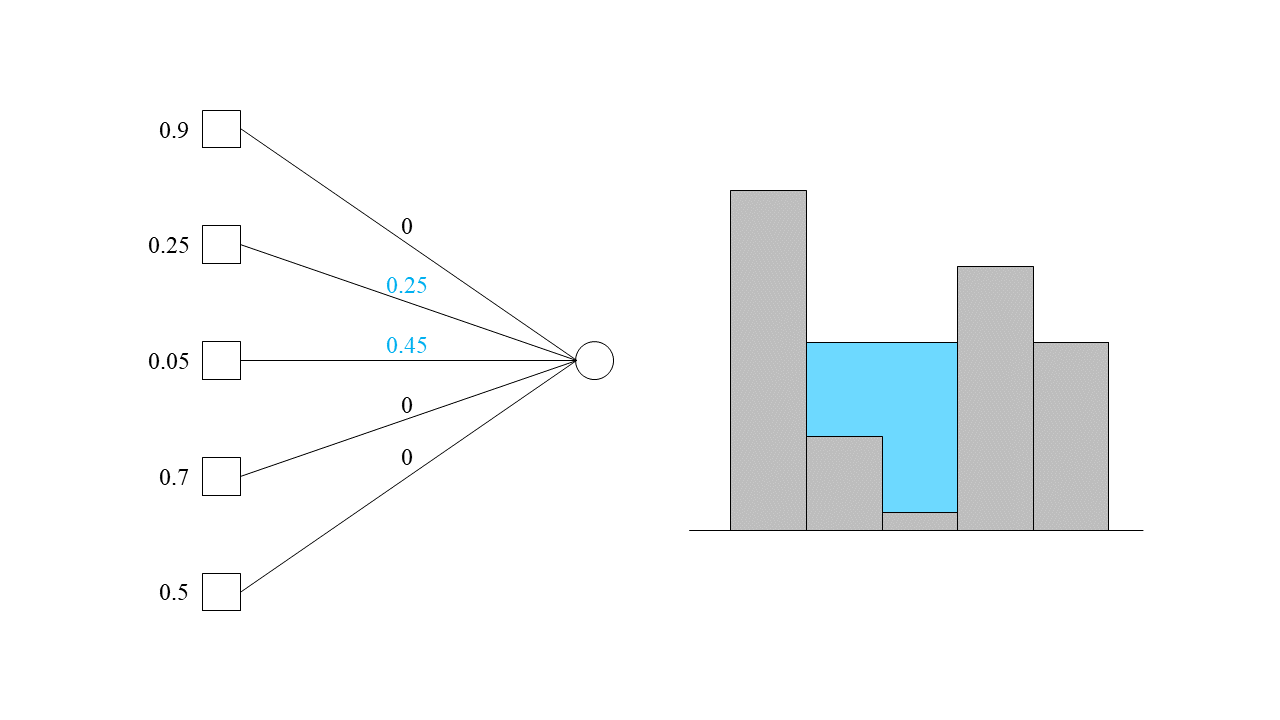
현재까지 총 0.7의 작업을 할당해 주었으므로, 여전히 0.3이 남은 상태입니다. 이제부터는 자연스럽게 두 번째, 세 번째, 그리고 다섯 번째 기계에까지 작업을 동시에 할당해 주도록 하겠습니다. 그러면 아래 상태일 때 1의 작업을 모두 할당하게 됩니다.
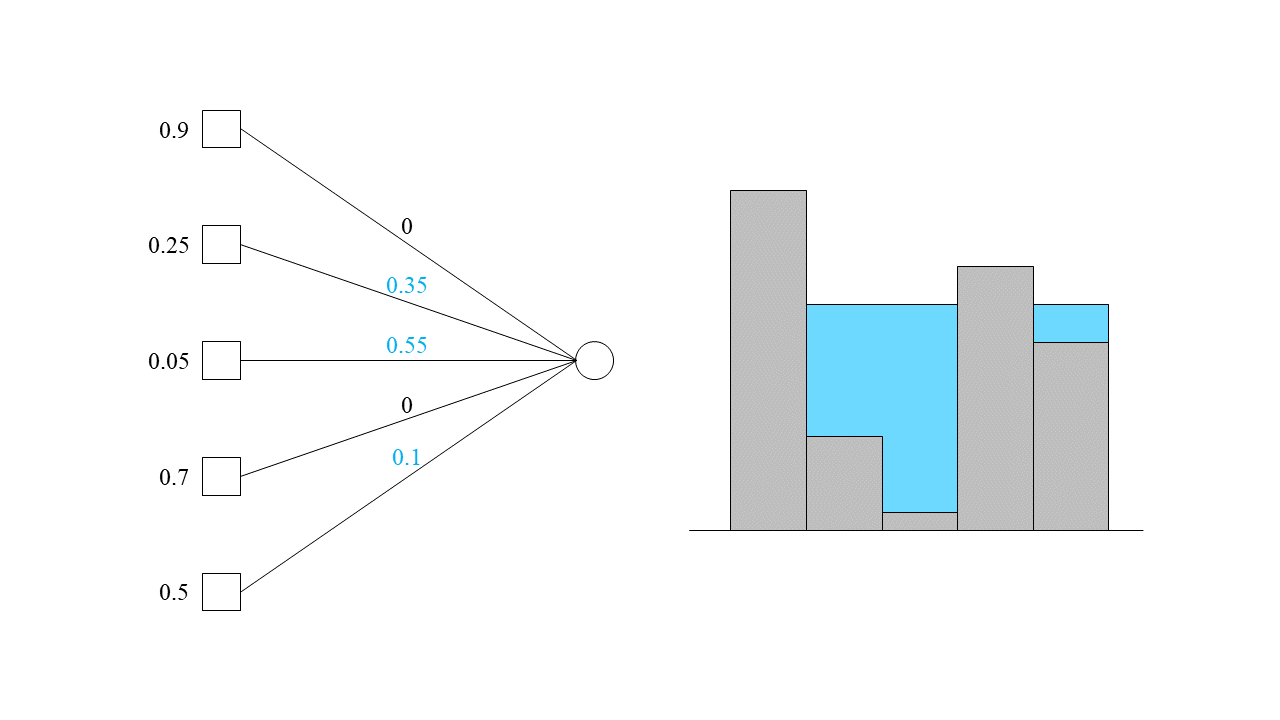
이렇게 작업을 할당해 준다면 우리가 원하는 대로 인접한 모든 기계에 동일한 부하를 줄 수 있게 됩니다. 물론 몇몇 기계에는 더 많은 부하가 실려있을 수 있습니다. 하지만 이는 이번 작업이 들어오기 전부터 이미 높은 부하를 가졌을 때뿐입니다. 그러한 기계에다가는 작업을 할당하지 않습니다.
고려하지 않은 경우가 하나 있습니다. 각 기계는 합해서 최대 1의 작업량을 할당 받을 수 있습니다. 따라서 작업을 넣는 작업을 진행하기 전에 인접한 기계들이 모두 부하가 높은 상황이라면, 작업을 인접한 기계에 모두 할당해 주지 못할 수 있습니다. 기존의 결정을 번복할 수 없으므로 인접한 기계가 모두 1의 부하를 받는 때가 오면, 남은 작업 조각들은 버리는 수밖에 없습니다.
이러한 방식으로 동작하는 알고리즘을 물 채우기 알고리즘(water-filling algorithm)이라고 부릅니다. 알고리즘이 동작하는 것을 보면 그러한 이름이 붙은 것이 직관적으로 다가올 것입니다. 새로운 작업이 도착했을 때, 각 인접한 기계들마다 할당받을 수 있는 여유분을 깊이로 하는 통에다가 용량이 1인 물을 붓는 것으로 생각할 수 있기 때문입니다. 들어간 물은 평평한 수면을 이룰 것이므로 종국적으로 인접한 기계들은 동일한 부하를 받게 될 것입니다. 만약 통의 깊이가 얕다면 모든 물을 부을 수 없을 것이고, 이때는 남은 물을 버려야 하겠습니다.
위 내용을 정형화하면 아래와 같이 적을 수 있습니다. 여기서
알고리즘 1. 물 채우기 알고리즘
초기 입력: 기계
출력: 할당
- 매 시각 작업
- 인접한 기계
- 인접한 기계
- 인접한 기계
알고리즘 분석
이제 알고리즘을 분석해 보도록 하겠습니다. 아래의 논의는 이전 글을 참고하시면 이해하기 쉽습니다.
온라인 이분 매칭 랭킹 알고리즘 (Ranking Algorithm for Online Bipartite Matching)
지난번에 온라인 이분 매칭 문제(online bipartite matching problem)에 대해서 알아 보았습니다. 그 문제는 다음과 같이 정의되었습니다. 처음에는 가용할 수 있는 택시 몇 대가 주어진다. 이후 시간이 흐
gazelle-and-cs.tistory.com
앞에서 우리는 알고리즘의 출력
이 LP의 쌍대는 아래와 같습니다.
두 LP는 다음의 유용한 성질을 갖습니다.
정리 1. LP 쌍대성
LP (P)에 가능한 임의의 해
따라서 만약 우리가
그러한
쌍대 문제 (D)에 가능한 해는 직관적으로 무엇에 해당할까요? 한번
이분 매칭의 쌍대 문제가 정점 덮개를 표현한다는 사실은 그다지 놀라운 일이 아닙니다. 둘 사이의 연관성은 다음의 유명한 정리에서 확연히 드러납니다.
정리 2. 쾨니그의 정리
어떤 이분 그래프가 주어졌을 때, 이분 그래프의 최대 매칭의 크기는 최소 정점 덮개의 크기와 동일하다.
위 정리가 궁금하신 분들은 아래의 글을 참고하시기 바랍니다.
쾨니그의 정리 (Kőnig's Theorem)
이 글은 홀의 정리 (Hall's Theorem)와 밀접한 연관이 있습니다. 필요한 경우에는 이를 참조하세요.2019/01/28 - [조합론적 최적화] - 홀의 정리 (Hall's Theorem) 무언가를 최적화시키는 문제를 보면 생각보
gazelle-and-cs.tistory.com
쾨니그의 정리를 통해 우리는 이분 그래프

각 조건을 만족하는 이유를 논의해 보겠습니다. 먼저, 만약
각설하고, 우리의 목표가 무엇이었는지 다시 생각해 보겠습니다. 우리의 목표는 알고리즘의 출력
문제는 알고리즘이 동작하는 도중에는 전체 입력이 어떻게 될지 모르므로
이번에는 작업의 경우를 생각해 봅시다. 어떤 작업을 처리한 후에 인접한 작업들의 부하가 작다면, 이 작업은
정리하자면 다음과 같습니다.
- 각 기계
- 각 작업
기계에 할당된 부하는
이렇게 정의된
정리 3. 가능한 쌍대 해
[증명]
남은 것은 식 (1)을 만족하는 적절한
정리 4. 알고리즘의 경쟁성
알고리즘의 출력
[증명] 편의를 위해
각
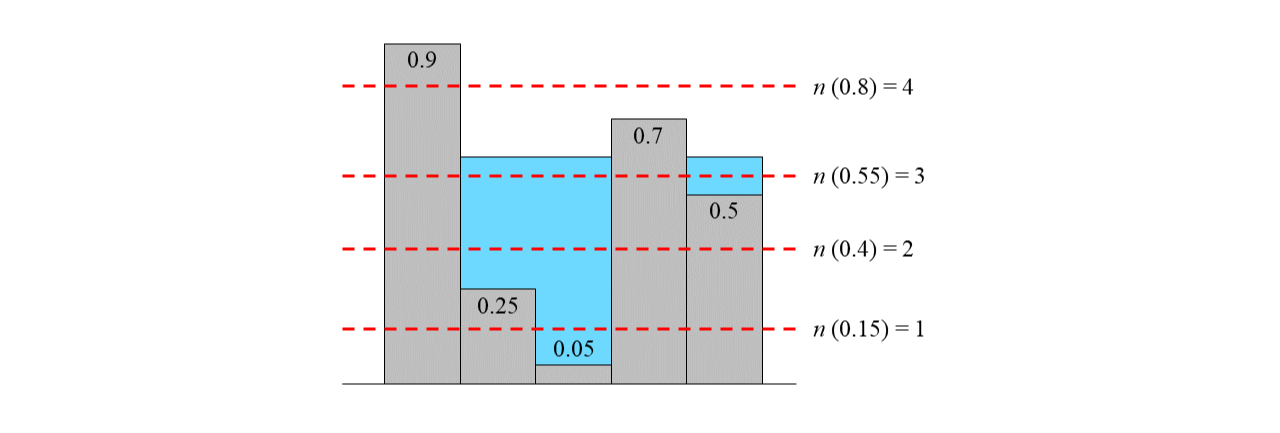
직관적으로 설명하면,
이 정의를 활용하면
이제
마지막으로
이를 모두 조합하면,
이제 남은 것은 적절한
마치며
이것으로 온라인 분수 이분 매칭 문제에 대한 설명을 마칩니다. 특히, 본문에서는 이 문제를
고맙습니다. :)
참고자료
[1] Bobby Kleinberg. Lecture note of CS 6820 Analysis of Algorithms, Cornell University, Fall 2012. [Link]
'온라인 알고리즘 > Online matching' 카테고리의 다른 글
| 온라인 이분 매칭 경쟁비 상한 (Upper Bound of Competitive Ratio for Online Bipartite Matching) (2) | 2024.03.12 |
|---|---|
| 온라인 메트릭 이분 매칭 (Online Metric Bipartite Matching) (0) | 2022.02.26 |
| 온라인 가중치 이분 매칭 (Online Weighted Bipartite Matching) (0) | 2021.02.14 |
| 온라인 이분 매칭 랭킹 알고리즘 (Ranking Algorithm for Online Bipartite Matching) (0) | 2021.01.09 |
| 온라인 이분 매칭 (Online Bipartite Matching) (0) | 2020.11.07 |



