
이 포스트에서 다룰 최소 신장 트리(minimum spanning tree, MST) 문제는 매우 유명한 조합론적 최적화 문제입니다. 아마 이 글을 읽으러 들어오셨다면 아무래도 학부 자료 구조나 알고리즘 수업 시간에 이 문제가 어떤 문제인지에 대해서 들어 보셨을 것입니다. 굳이 다시 정의를 해 보자면, 이 문제는 간선마다 비용이 정의된 그래프 위에서 최소의 비용으로 모든 정점을 연결하는 트리를 찾는 문제입니다.
수업 시간에 이 문제를 다루면서 분명 이 문제를 해결하는 알고리즘에 대해서도 함께 배우셨을 것입니다. 적어도 다음 두 알고리즘은 배웠을 텐데, 바로 크루스칼의 알고리즘(Kruskal's algorithm)과 프림의 알고리즘(Prim's algorithm)입니다. 두 알고리즘 모두 한두 문장으로 설명이 가능할 정도로 간단하고 직관적입니다. 크루스칼의 알고리즘은 비용이 작은 간선부터 차례대로 보면서 순환을 만들지 않으면 해에 넣고 보는 알고리즘을 일컬으며, 프림의 알고리즘은 한 정점을 기준으로 그 정점에 연결된 정점과 연결되지 않은 정점을 잇는 간선 중 비용이 가장 작은 것을 매번 취해 가는 알고리즘을 말합니다. 두 알고리즘이 동작하는 것을 곰곰이 생각해 본다면 실지로 MST를 출력한다는 것이 믿기기는 할 것입니다.
다만 직관이 증명은 아닙니다. 세상에는 직관에 반하는 일도 종종 발생하기 마련이죠. 따라서 증명하기 전까지는 알고리즘의 동작이 올바르다고 단정지을 수 없습니다. 이번 포스트에서는 상기한 두 알고리즘이 어째서 진짜 MST를 출력하는 것인지 엄밀하게 보이겠습니다. 이를 위해서는 (알고리즘과는 관련 없이) MST가 갖는 흥미로운 성질인 절단 성질(cut property)에 대해서 먼저 알아야 합니다. 이후 어찌하면 이 성질을 활용하여 크루스칼의 알고리즘과 프림의 알고리즘이 증명될 수 있는지 보도록 하겠습니다.
본문에서 크루스칼의 알고리즘과 프림의 알고리즘의 동작에 대해서 개괄적으로 설명을 할 예정입니다만, 이 글은 두 알고리즘의 정확성(correctness)에 초점이 맞추어져 있는 만큼 수행 시간에 대한 분석은 하지 않습니다. 참고로 프림의 알고리즘은 다익스트라의 알고리즘(Dijkstra's algorithm)과 거의 동일합니다. 게다가 그 알고리즘과 동일한 시간 복잡도를 갖습니다. 관련하여 제 이전 글을 참고하시기 바랍니다.
2021.10.09 - [조합론적 최적화/Shortest path] - 다익스트라의 알고리즘 (Dijkstra's Algorithm)
다익스트라의 알고리즘 (Dijkstra's Algorithm)
최단 경로 문제(shortest path problem)는 가장 유명한 조합론적 최적화 문제 중 하나로, 이름에서 유추할 수 있듯이 다양한 분야에서 널리 활용되는 문제입니다. 지난 포스트에서는 이 문제를 정확히
gazelle-and-cs.tistory.com
반면 크루스칼의 알고리즘은 수행 시간과 관련하여 흥미로운 내용이 많이 있습니다. 다음에 기회가 되면 꼭 포스팅해 볼 수 있도록 하겠습니다.
정의 및 기호
본문에서 사용될 정의와 기호 몇 가지를 소개하겠습니다. 아래에서 열심히 사용되니 잘 숙지하고 본문을 읽는 것을 추천합니다.
[문제의 입력]
먼저 MST 문제의 입력으로는 어떤 방향이 없는(undirected), 연결된(connected) 그래프 \(G = (V, E)\)와 각 간선 위의 비용 \(c : E \to \mathbb{Q} \)가 주어집니다. 이때 \(c\)는 같은 값을 가질 수 있습니다. 다시 말해, 어떤 서로 다른 두 간선의 비용이 동일할 수 있습니다.
[트리, 신장 트리, 신장 트리의 비용]
트리(tree)는 연결된, 순환이 없는(acyclic) 그래프를 말합니다. 입력 그래프 \(G = (V, E)\)에 대해, 신장 트리(spanning tree)는 \(V\)가 모두 참여하면서 \(E\)에 속한 간선만으로 이루어진 트리를 의미합니다. 신장 트리 \(T\)가 주어졌을 때, 그것의 비용 \(c(T)\)는 \(T\)에 속한 간선의 비용의 총합, 즉, \[ c(T) := \sum_{e \in T} c(e) \]로 정의하겠습니다. MST 문제의 목표는 최소의 비용을 갖는 신장 트리를 찾는 것입니다.
[정점의 분할]
정점의 분할(partition)은 쉽게 말해 모든 정점을 비어 있지 않은 부분 집합으로 나누어 놓은 것을 의미합니다. 엄밀히 말해, 어떤 \(\mathcal{U} = \{U_1, U_2, \cdots, U_k\}\)가
- 각 \(i\)에 대해, \(U_i \subseteq V\)이고 \(U_i \neq \emptyset\)
- \( \bigcup_{i = 1}^k U_i = V \)
- 임의의 두 \(i, j\)에 대해, \(U_i \cap U_j = \emptyset\)
를 모두 만족한다면, 우리는 이러한 \(\mathcal{U}\)를 정점의 분할이라고 부릅니다.
[횡단하는 간선]
어떤 정점의 분할 \(\mathcal{U} = \{U_1, \cdots, U_k\} \)가 주어졌을 때, \(\mathcal{U}\)의 서로 다른 집합에 속한 정점을 잇는 간선이 있다면, 우리는 그 간선을 보고 \(\mathcal{U}\)를 횡단(cross)한다고 부릅니다.
[존중하는 분할]
반대로 어떤 간선의 부분집합 \(S \subseteq E\)가 주어졌을 때, 어떤 정점의 분할 \( \mathcal{U} = \{U_1, \cdots, U_k\} \)가 다음을 만족한다고 합시다.
- \(S\)의 임의의 간선에 대해, 그 양 끝점(endpoint)이 모두 같은 \(\mathcal{U}\)의 한 부분집합에 속한다. 즉, 임의의 \( (u, v) \in S \)에 대해, \( u \in U_i \), \(v \in U_i\)인 \(i\)가 존재한다.
다시 말해, \(S\)의 모든 간선이 \(\mathcal{U}\)를 횡단하지 않는 경우입니다. 그럴 때 우리는 \(\mathcal{U}\)가 \(S\)를 존중(respect)한다고 말하겠습니다.

절단 성질
서론에서 언급하였듯이 이 글의 목표는 크루스칼의 알고리즘과 프림의 알고리즘을 절단 성질을 이용하여 증명하는 것입니다. 먼저 절단 성질이 무엇인지부터 말씀드리겠습니다.
정리 1. 절단 성질 (cut property)
어떤 MST \(T\)와 그것의 진부분집합 \(S \subsetneq T\), 그리고 \(S\)를 존중하는 \(\{V\}\)가 아닌 어떤 정점의 분할 \(\mathcal{U}\)가 주어졌다고 하자. \( \mathcal{U} \)를 횡단하는 간선 중에서 가장 비용이 작은 간선을 \(e\)라고 하자. (만약 여러 개가 있으면, 아무거나 하나 고른다.) 그러면 \(S + e\)는 (\(T\)와는 다를 수도 있는) 어떤 MST \(T'\)의 부분집합이다.
위 정리의 명제에서 몇 가지 짚고 넘어갈 부분이 있습니다.
- \(S\)는 \(T\)의 진부분집합입니다. 만약 \(S = T\)라면 이를 존중하는 정점의 분할은 \(\{V\}\) 밖에 없습니다. 따라서 이 분할을 횡단하는 간선은 존재하지 않죠. 하지만 \( S = T \)라면 이미 그 자체로 MST이므로 굳이 무언가를 더 찾을 필요는 없습니다.
- \(e\)는 꼭 존재합니다. \( \mathcal{U} \)가 \(\{V\}\)가 아니라면 이 분할을 횡단하는 간선은 반드시 존재해야 합니다. 그렇지 않다면 \( \mathcal{U} \)의 한 부분집합에 속한 정점에서 다른 부분집합에 속한 정점까지 향하는 경로가 존재하지 않게 되며, 이는 입력 그래프가 연결되어 있다는 사실에 위배됩니다.
- \(S + e\)를 포함할 MST는 \(T\)가 아닐 수도 있습니다. 이러한 일이 발생할 수 있는 이유는 서로 다른 두 간선이 같은 비용을 가질 수 있기 때문입니다. 그러면 동일한 비용을 갖는 신장 트리가 생길 수 있습니다. 그럼에도 위 정리가 여전히 의미가 있는 이유는 어차피 최종적으로 우리가 출력할 것은 특정 MST가 아닌 아무 MST이기 때문입니다.
정리 1을 증명하기 위해서는 트리와 관련된 몇 가지 보조 정리들이 필요합니다. 첫 번째는 트리의 정의에 의해 성립하는 성질입니다. 아래에서 경로가 단순(simple)하다는 것의 의미는 경로 상에서 한 번 지난 정점을 다시 지나지 않는다는 것을 말합니다.
정리 2. 트리에서 정점 쌍의 경로의 유일성
어떤 트리가 주어졌을 때, 그 위의 두 정점 쌍의 경로는 단순하며 유일하다.
[증명] 만약 두 정점 쌍의 경로가 존재하지 않다면, 트리의 연결성에 위배됩니다. 만약 경로가 단순하지 않다면 한번 지난 정점을 다시 지날 수 있다는 의미이므로 순환이 존재한다는 뜻이고, 이는 트리에 순환이 없다는 성질에 모순이 됩니다. 이번에는 서로 다른 두 정점 \(u, v\)에 대해, 두 정점을 잇는 경로가 \(T\) 위에 두 개 있다고 해 봅시다. 각각 \[ P_1 := \langle u = a_1, a_2, \cdots, a_p = v \rangle, \; P_2 := \langle u = b_1, b_2, \cdots, b_q = v \rangle \]라고 부르겠습니다. \(a_1 = b_1 = u\)이므로 분명 \( a_i = b_i \)이지만 \( a_{i + 1} \neq b_{i + 1} \)를 만족하는 \(i\)가 반드시 존재할 것입니다. 이를 만족하는 \(i\) 중에서 가장 작은 값을 가지고 오겠습니다. 또한 \( a_p = b_q = v \)이므로 분명 \( a_{j - 1} \neq b_{k - 1} \)이나 \( a_j = b_k \)을 만족하는 \( j, k \)도 존재할 것입니다. 앞에서 정한 \(i\) 이후에 처음으로 그렇게 되는 \(j, k\)를 갖고 오겠습니다. 그러면 \(a_i\)에서 \(P_1\)을 따라 \(a_j = b_k\)로 간 다음 \(P_2\)를 따라 \(b_i\)로 돌아오는 방법, 즉, \[ \langle a_i, a_{i + 1}, \cdots, a_{j-1}, a_j = b_k, b_{k - 1}, \cdots, b_{i + 1}, b_i \rangle \]는 순환(cycle)이 됩니다. 이는 트리에 순환이 없다는 성질에 위배됩니다. ■
다음은 절단 정리의 증명에서 활용할 연산에 대한 내용입니다.
정리 3. 신장 트리 간선 교체 연산
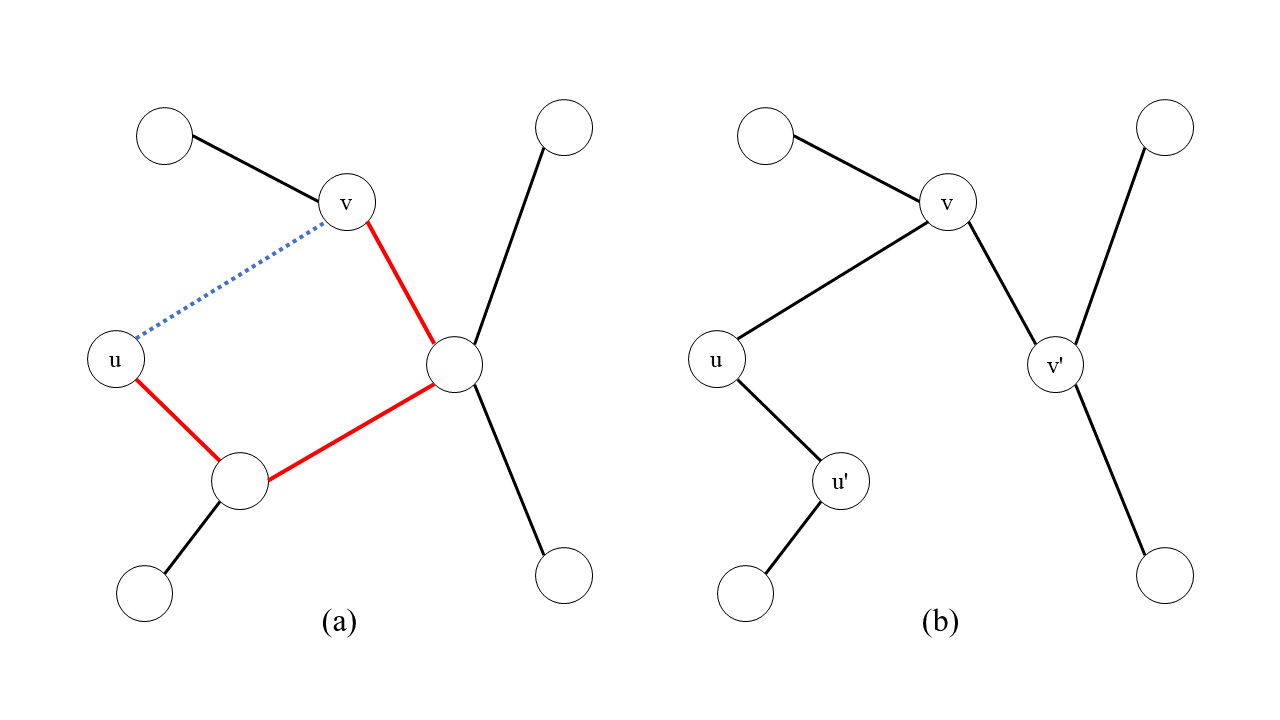
어떤 신장 트리 \(T\)와 그 위에 있지 않은 어떤 간선 \((u, v) \in E \setminus T\)가 주어졌다고 하자. \(T\) 위에서 \(u\)와 \(v\)를 잇는 유일한 경로를 \(P\)라고 할 때, 그 경로 위의 임의의 간선 \((u', v') \in P\)에 대해, \(T\)에 \((u, v)\)를 넣고 \((u', v')\)을 제거한 것, 즉, \[ T' := T + (u, v) - (u', v') \]도 신장 트리이다.
[증명] 먼저 \(T'\)에 순환이 존재하지 않음을 논증하겠습니다. \(T + (u, v)\)에는 순환이 정확히 한 개 존재해야 합니다. 그렇지 않으면 \(T\)에 \(u\)와 \(v\)를 잇는 경로가 두 개 이상이라는 뜻이며, 이는 정리 2에 의해 모순이 됩니다. 유일한 그 순환은 분명 \(P + (u, v)\)입니다. \(P\)가 단순 경로이므로 \(P + (u, v)\)에서 \( (u', v') \)를 제거하면 더이상 순환이 되지 못합니다. 따라서 \( T' \)에는 순환이 존재하지 않습니다.
이제 \(T'\)이 \(G\)를 신장하며 연결한다는 것을 보이겠습니다. 임의의 두 정점 \(x, y \in V\)에 대해, \(T\) 위에서 \(x\)와 \(y\)를 잇는 유일한 단순 경로를 \( P^T_{x,y} \)라고 부르겠습니다. 만약 \( (u', v') \not\in P^T_{x, y} \)라면 해당 간선들은 모두 \(T'\)에도 있으므로 \(T'\) 위에도 \(x\)와 \(y\)를 잇는 경로가 존재합니다. 따라서 남은 경우는 \( (u', v') \in P^T_{x, y} \)인 경우입니다. 이 경우에는 \( P^T_{x, y} \)에서 \((u', v')\)를 \( P + (u, v) - (u', v') \)로 교체하는 방법으로 \(x\)와 \(y\)를 잇는 \(T'\) 위의 경로를 만들 수 있습니다. ■
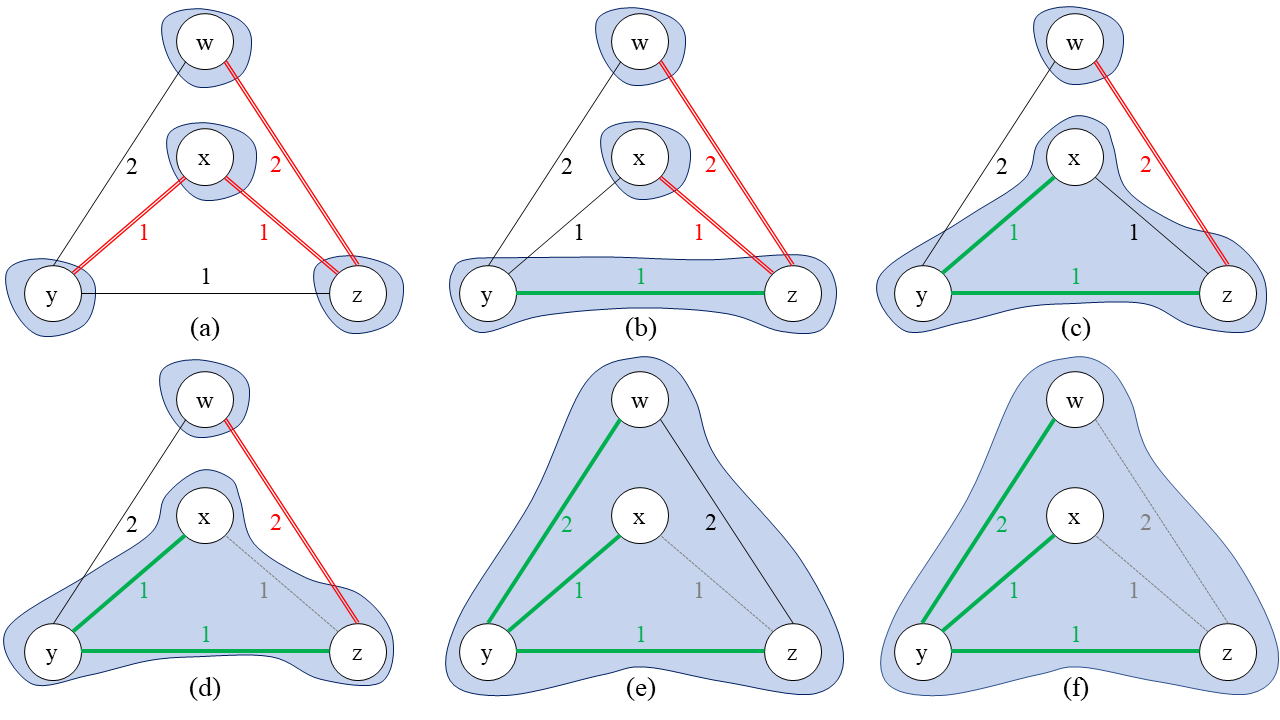
이제 앞에서 본 정리들을 활용하여 절단 성질을 증명할 수 있습니다.
[정리 1 증명] 만약 \(e \in T\)라면 \( S + e \subseteq T \)이므로 \(T' := T\)로 두면 명제가 곧장 성립합니다. 따라서 \(e \not\in T\)에 대해서만 논증하면 모든 증명이 끝납니다. \(e = (u, v)\)라고 하겠습니다. \(T\) 위에서 \(u\)와 \(v\)를 잇는 유일한 단순 경로를 \(P\)라고 부르겠습니다. \((u, v)\)는 \( \mathcal{U} \)를 횡단하므로 \(u\)와 \(v\)는 \(\mathcal{U}\)의 서로 다른 부분집합에 각각 속한 상태입니다. 따라서 \(P\) 위에도 \(\mathcal{U}\)를 횡단하는 간선이 반드시 하나는 존재해야 합니다. 그 간선을 \((u', v')\)이라고 부르겠습니다.
먼저, 정리 3에 의해서 \( T' := T + (u, v) - (u', v') \)도 또 다른 신장 트리라는 사실을 도출할 수 있습니다. 그런데 \((u', v')\)도 \(\mathcal{U}\)를 횡단하는 간선이라는 점과 \(e = (u, v)\)의 정의에 의해 \( c(u, v) \leq c(u', v') \)가 되어 \[ c(T') = c(T) + c(u, v) - c(u', v') \leq c(T) \]를 이끌어 낼 수 있습니다. \(T\)가 MST였으므로 \(T'\)도 응당 MST가 됩니다. 명제의 조건에서 \(\mathcal{U}\)가 \(S\)를 존중한다고 했으므로 \((u', v') \not\in S\)를 만족합니다. 그러므로 \(S + e \subseteq T'\)가 됩니다. ■
MST 알고리즘 증명
이전 절에서는 절단 성질이 무엇인지 알아 보고 어째서 그 성질이 성립하는지를 증명하였습니다. 이제 이 성질을 활용하여 크루스칼의 알고리즘과 프림의 알고리즘이 어째서 MST를 출력하는지를 증명해 보도록 하겠습니다. 이번 포스트에서는 두 알고리즘의 수행 시간에 대해서는 논의하지 않을 예정이므로 아래에서는 알고리즘을 최대한 개괄적으로 기술하였음을 알립니다.
크루스칼의 알고리즘
많은 분들이 대개 알고 있는 크루스칼의 알고리즘은 다음과 같이 동작합니다.
알고리즘 1. 크루스칼의 알고리즘 (Kruskal's algorithm)
입력: 그래프 \(G = (V, E)\), 비용 \(c : E \to \mathbb{Q}\)
출력: MST
- \(S \gets \emptyset \)
- \(E\)를 비용의 오름차순으로 정렬한다.
- 정렬된 \(E\)의 각 간선 \(e=(u,v)\)에 대해 아래를 수행한다.
- \(u\)와 \(v\)가 \((V, S)\)의 서로 다른 연결 성분(connected component)에 속해 있으면, 아래를 수행한다.
- \( S \gets S + e \)
- \(u\)와 \(v\)가 \((V, S)\)의 서로 다른 연결 성분(connected component)에 속해 있으면, 아래를 수행한다.
- \(S\)를 반환한다.
단계 3-a에서는 정점의 집합을 \(V\), 간선의 집합을 \(S\)로 하는 그래프 \( (V, S) \)의 연결 성분을 고려합니다. 이때, 연결 성분은 서로 도달 가능한(reachable) 정점들을 극대로(maximally) 포함시킨 부분 그래프(subgraph)를 의미합니다. 단계 3-a에서 진행하는 것은 결국 \((V, S)\)에서 현재 고려하는 간선 \(e\)의 양 끝점이 서로 도달 가능하지 않은 경우 \(e\)를 \(S\)에 추가하는 것입니다.
이제 크루스칼의 알고리즘을 분석해 보겠습니다. 이를 위해서 위 알고리즘에 몇 개의 연산을 추가하도록 하겠습니다. 추가된 연산은 빨간색 글씨로 굵게 적었습니다.
알고리즘 2. (가상의 연산이 추가된) 크루스칼의 알고리즘
입력: 그래프 \(G = (V, E)\), 비용 \(c : E \to \mathbb{Q}\)
출력: MST
- \(S \gets \emptyset \)
- \(T \gets\) 아무 MST
- \( \mathcal{U} \gets \{ \{v\} \mid v \in V \} \)
- \(E\)를 비용의 오름차순으로 정렬한다.
- 정렬된 \(E\)의 각 간선 \(e=(u,v)\)에 대해 아래를 수행한다.
- \(u\)와 \(v\)가 \((V, S)\)의 서로 다른 연결 성분(connected component)에 속해 있으면, 아래를 수행한다.
- \(T \gets \) 절단 성질로부터 보장된 \(S + e\)를 포함하는 어떤 MST
- \(\mathcal{U}\)에서 \(u\)가 속한 연결 성분과 \(v\)가 속한 연결 성분을 합친다.
- \(S \gets S + e\)
- \(u\)와 \(v\)가 \((V, S)\)의 서로 다른 연결 성분(connected component)에 속해 있으면, 아래를 수행한다.
- \(S\)를 반환한다.
추가된 연산은 알고리즘 1에 있던 기존 연산에 영향을 주지 않는 것을 확인하시기 바랍니다. 그러므로 알고리즘 1과 알고리즘 2의 출력은 (\(E\)를 동일한 순서로 정렬했다면) 항상 동일합니다. 따라서 알고리즘 2가 어떤 MST를 출력한다면, 알고리즘 1도 올바르게 MST를 출력한다는 사실을 알 수 있습니다.
알고리즘 2의 동작을 곰곰이 살펴 봅시다. \(\mathcal{U}\)는 문제가 될 것이 없습니다. 처음에 각 정점을 부분집합으로 갖는 분할을 \(\mathcal{U}\)에 저장하는 것도 충분히 가능하며, 단계 5-a-ii에서 두 정점이 속한 연결 성분을 찾아서 병합하는 작업도 (시간에 구애받지 않으면) 그다지 어려운 일이 아닙니다.
문제는 \(T\)입니다. 이는 초깃값으로 아무 MST를 받습니다. 게다가 단계 5-a-i에서는 새로운 MST로 갈아 끼울 수도 있습니다. 우리의 최종적인 목표가 아무 MST를 하나 찾는 것인데도 말이죠. 이는 더없이 말도 안 되는 이야기입니다. 하지만 앞에서 우리는 \(T\)를 정의하지 않은 알고리즘 1에서도 동일한 \(S\)를 반환한다는 사실을 논의하였습니다. 이때 만약 알고리즘 2에서 \(S\)가 종국에는 \(T\)와 동일해진 채로 출력이 된다면, 알고리즘 2, 나아가 알고리즘 1이 MST를 출력한다는 결과를 도출할 수 있습니다. 이것이 바로 우리의 증명 방향입니다. 이 과정에서 \(T\)는 오로지 분석의 용도로만 사용될 것이므로 알고리즘 2에서 \(T\)가 있다고 가정하여도 무방합니다.
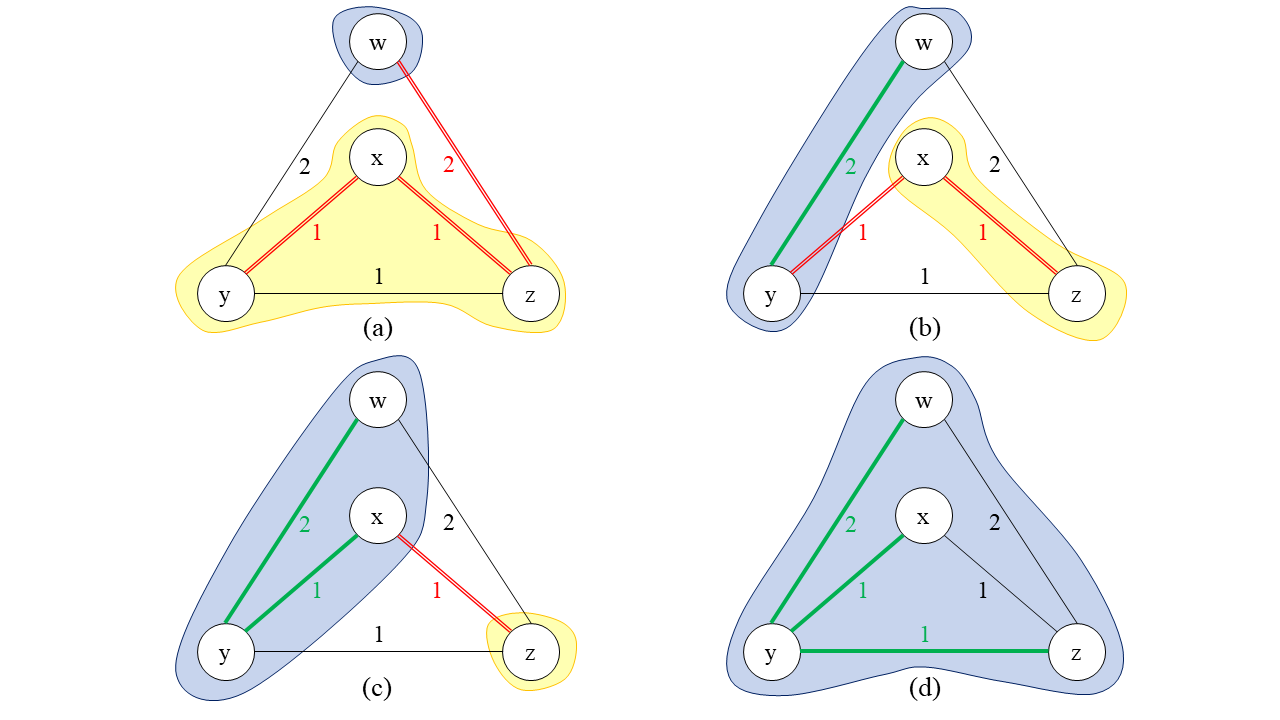
단계 5-a-i에서는 \(T\)를 절단 성질로부터 보장된 MST로 업데이트합니다. 그러기 위해서는 먼저 절단 성질을 사용할 수 있는지를 논증해야 합니다. 첫 번째로 \(\mathcal{U}\)가 \(S\)를 존중한다는 것을 보이겠습니다.
정리 4. \(S\)를 존중하는 \(\mathcal{U}\)
단계 3이 수행된 직후와 매번 단계 5-a를 수행한 후, \( \mathcal{U} \)는 \( (V, S) \)의 연결 성분의 모임이다. 따라서 \(\mathcal{U}\)는 \(S\)를 존중한다.
[증명] 귀납적으로 보이겠습니다. 기저 경우(base case)로 단계 3이 수행된 직후에는 \(S = \emptyset\)이므로 \((V, S)\)의 모든 정점들은 서로 고립된(isolated) 상태입니다. 그때 \( \mathcal{U} \)는 \( \{ \{v\} \mid v \in V \} \)로 정의되었으므로 명제가 자명하게 성립합니다. 이제 귀납 가정(induction hypothesis)으로 언젠가 단계 5-a를 수행하기 직전에 \(\mathcal{U}\)가 \( (V, S) \)의 연결 성분을 모아 놓은 것과 동일하다고 해 보겠습니다. 단계 5-a가 수행될 조건은 \(u\)와 \(v\)가 서로 다른 연결 성분에 속할 때입니다. 단계 5-a-ii에서 우리는 해당 작업을 정확히 진행합니다. ■
다음은 \(e = (u, v)\)가 \( \mathcal{U} \)를 횡단하는 간선 중 최소의 비용을 갖는다는 것입니다.
정리 5. 최소의 비용을 갖는 횡단 간선 \(e\)
매번 단계 5-a가 수행되려고 할 때의 \(e\)는 그때의 \( \mathcal{U} \)를 횡단하는 최소 비용의 간선이다.
[증명] 알고리즘에서 우리는 \(E\)를 오름차순으로 정렬하였습니다. 따라서 만약 현재의 \(e\)가 들어오기 전에 들어온 간선들이 모두 현재의 \(\mathcal{U}\)를 횡단하지 않는다는 사실을 보이면 정리의 명제를 증명하게 됩니다. 그러한 간선 \(e'\)은 두 종류로 나뉩니다.
- 이전에 단계 5-a의 조건을 만족한 경우. 이때는 현재의 \(S\)에 \(e'\)이 포함되어 있습니다. 정리 4에 의해 현재의 \(\mathcal{U}\)는 현재의 \(S\)를 존중하므로 \(e'\)은 현재의 \(\mathcal{U}\)를 횡단할 수 없습니다.
- 이전에 단계 5-a의 조건을 만족하지 못한 경우. 이때는 \(e'\)이 그때의 \(\mathcal{U}\)조차 횡단하지 못했다는 뜻입니다. 우리는 알고리즘에서 \(\mathcal{U}\)를 관리할 때 계속 합치기만 했습니다. 따라서 \(e'\)은 현재의 \(\mathcal{U}\)에서도 횡단 간선이 되지 못합니다.
모든 경우에 대해서 \(e'\)이 횡단하지 못함을 보였으니 증명이 완성됩니다. ■
아래는 전체 증명에서 가장 중요한 정리입니다. 이를 증명할 때 이전 절에서 공부한 절단 성질이 드디어 활용됩니다.
정리 6. \(S\)를 포함하는 MST \(T\)
단계 3이 수행된 직후와 매번 단계 5-a를 끝낸 후 \(T\)는 항상 \(S \subseteq T\)를 만족하는 어떤 MST이다.
[증명] 알고리즘의 진행에 따라 귀납적으로 증명하겠습니다. 단계 3이 수행된 후에는 \(S\)는 공집합, \(T\)는 아무 MST로 설정됩니다. \(S = \emptyset \subseteq T\)는 자명합니다. 따라서 기저 경우는 쉽게 성립함을 알 수 있습니다. 이제 귀납 조건으로, 언젠가 단계 5-a를 수행하기 직전 \(T\)가 \(S \subseteq T\)를 만족하는 어떤 MST라고 하겠습니다. 이때의 \(T\), \(S\), \(\mathcal{U}\), \(e\)가 절단 성질의 조건을 모두 만족함을 보이겠습니다.
- \(T\) : 귀납 가정에 의해 어떤 MST입니다.
- \(S\) : 귀납 가정에 의해 \(S \subseteq T\)입니다. 그런데 단계 5-a가 수행되기 위해서는 현재 고려하는 간선 \(e\)의 양 끝점 \(u\), \(v\)가 \((V, S)\)의 서로 다른 연결 성분에 있어야 합니다. 만약 \(S = T\)라면 \(T\)가 신장 트리라는 사실과 정리 2에 의해 그러한 \(u\), \(v\)는 존재하지 않습니다. 따라서 그때의 \( S \)는 필시 \(T\)의 진부분집합이어야 합니다.
- \(\mathcal{U}\) : 정리 4에 의해서 \(\mathcal{U}\)는 \((V, S)\)의 연결 성분의 모임입니다. 이는 \(S\)가 \(T\)의 진부분집합이라는 사실과 함께 \(\mathcal{U}\)가 \(\{V\}\)가 아니면서 \(S\)를 존중하는 분할이라는 사실을 도출합니다.
- \(e\) : 정리 5에 의해 현재 고려하는 \(e\)는 \(\mathcal{U}\)를 횡단하는 간선 중 최소의 비용을 갖습니다.
따라서 우리는 단계 5-a를 수행하기 직전의 \(T\), \(S\), \(\mathcal{U}\), \(e\)가 절단 성질의 조건을 모두 만족한다는 것을 알 수 있으며, 이를 적용하면 \(S + e\)를 포함하는 어떤 MST \(T'\)도 반드시 존재한다는 사실을 도출할 수 있습니다. 단계 5-a가 끝나면 알고리즘에서는 \(T\)를 \(T'\)으로 \(S\)를 \(S + e\)로 업데이트합니다. 따라서 단계 5-a가 수행된 후에도 \(T\)는 \(S \subseteq T\)를 만족하는 어떤 MST입니다. ■
드디어 위 정리들을 활용하면 크루스칼의 알고리즘이 올바르게 동작한다는 것을 엄밀하게 증명할 수 있습니다.
정리 7. 크루스칼의 알고리즘의 정확성
알고리즘 2는 올바르게 동작한다. 즉, 어떤 MST를 출력한다.
[증명] 먼저 알고리즘 2가 출력하는 \(S\)에 대해, \( (V, S) \)가 연결되어 있다는 것을 보이겠습니다. 만약 연결되어 있지 않다면, 정리 4에 의해 \( \mathcal{U} \)는 둘 이상의 연결 성분으로 이루어져 있을 것입니다. 그런데 문제를 정의할 때 입력되는 그래프 \(G = (V, E)\)는 연결되어 있다고 하였으므로 분명 \( \mathcal{U} \)를 횡단하는 간선이 하나는 존재해야 합니다. 그럼 알고리즘이 해당 간선 중 하나를 고려할 때 이를 \(S\)에 추가했을 것이므로 모순이 됩니다.
정리 6에 의해 우리는 최종적으로 출력하는 \(S\)가 어떤 MST \(T\)의 부분집합이라는 사실을 압니다. 그런데 앞에서 \((V, S)\)가 연결되어 있어야 한다고 했으므로 가능한 경우는 \(S = T\) 뿐입니다.따라서 알고리즘 2는 최종적으로 \(T\)를 출력합니다. ■
프림의 알고리즘
이제 프림의 알고리즘을 절단 성질을 활용하여 증명해 보겠습니다. 우리가 익히 아는 프림의 알고리즘은 개략적으로 아래와 같습니다.
알고리즘 3. 프림의 알고리즘 (Prim's algorithm)
입력: 그래프 \(G = (V, E)\), 비용 \(c : E \to \mathbb{Q}\)
출력: MST
- 아무 정점 \(r \in V\)를 설정한다.
- \(R \gets \{r\} \)
- \(S \gets \emptyset \)
- 아래를 총 \(|V| - 1\) 번 수행한다.
- 한 끝점은 \(R\), 다른 끝점은 \(V \setminus R\)에 있는 간선 중 비용이 가장 작은 것을 \(e = (u, v)\)라고 한다. 일반성을 잃지 않고 \(u \in R\), \(v \in V \setminus R\)이라고 하자.
- \(R \gets R + v\)
- \( S \gets S + e \)
- \(S\)를 반환한다.
크루스칼의 알고리즘을 증명할 때에도 그랬던 것처럼 가상의 연산을 아래와 같이 추가하도록 하겠습니다. 추가된 연산은 위와 동일하게 빨간색 글씨로 굵게 적었습니다.
알고리즘 4. (가상의 연산이 추가된) 프림의 알고리즘
입력: 그래프 \(G = (V, E)\), 비용 \(c : E \to \mathbb{Q}\)
출력: MST
- 아무 정점 \(r \in V\)를 설정한다.
- \(T \gets\) 아무 MST
- \(R \gets \{r\} \)
- \( \mathcal{U} \gets \{ R, V \setminus R \} \)
- \(S \gets \emptyset \)
- 아래를 총 \(|V| - 1\) 번 수행한다.
- 한 끝점은 \(R\), 다른 끝점은 \(V \setminus R\)에 있는 간선 중 비용이 가장 작은 것을 \(e = (u, v)\)라고 한다. 일반성을 잃지 않고 \(u \in R\), \(v \in V \setminus R\)이라고 하자.
- \(T \gets\) 절단 성질로부터 보장된 \(S + e\)를 포함하는 어떤 MST
- \(R \gets R + v\)
- \( \mathcal{U} \gets \{ R, V \setminus R \} \)
- \( S \gets S + e \)
- \(S\)를 반환한다.
추가된 연산은 기존의 단계에 영향을 주지 않으므로 위 두 알고리즘은 동일하게 동작합니다. 또한 \(T\)는 여전히 어불성설이지만, 오로지 분석에만 사용할 것이므로 정의하여도 괜찮다는 사실을 다시 강조합니다.
증명은 크루스칼의 알고리즘에서보다 간단한 편입니다. 절단 성질의 조건이 알고리즘의 동작에서 곧장 유도되는 경우가 많기 때문입니다. 먼저 \( \mathcal{U} \)에 대해서 논의해 보겠습니다. 아래 정리는 크루스칼의 알고리즘에서 정리 6에 대응합니다.
정리 8. \(S\)를 포함하는 MST \(T\)
단계 5가 수행된 직후 및 단계 6을 한 번씩 수행할 때마다 \(T\)는 항상 \(S \subseteq T\)를 만족하는 어떤 MST이다.
[증명] 귀납적으로 증명하겠습니다. 기저 경우로 단계 5가 수행된 후 \(S\)는 공집합으로 \(T\)는 아무 MST로 설정됩니다. 따라서 명제의 정리가 자명하게 성립합니다. 이제 귀납 조건으로 단계 6을 수행하기 직전에 \(T\)가 그때의 \(S\)를 포함하는 어떤 MST라고 하겠습니다. 그때의 \(T\), \(S\), \(\mathcal{U}\), \(e\)는 각각 아래의 이유로 절단 성질의 조건을 만족합니다.
- \(T\) : 귀납 가정에 의해 어떤 MST입니다.
- \(S\) : 귀납 가정에 의해 \(S \subseteq T\)입니다. 간단한 귀납법으로 단계 6을 그동안 \(k\) 번 수행했으면 그때의 \(S\)는 \( |S| = k \)를 만족함을 알 수 있습니다. 이번에 단계 6을 수행한다는 것은 아직 \(|S| < |V| - 1 = |T|\)라는 뜻입니다. 따라서 \(S \subsetneq T\)입니다.
- \(\mathcal{U}\) : 알고리즘의 동작을 잘 살펴 보면 \(R\)은 결국 \(r\)에서 \(S\)의 간선을 이용하여 도달 가능한 정점의 집합과 동일합니다. 그러므로 \(S\)의 모든 간선은 \( \mathcal{U} = \{R, V \setminus R\} \)를 횡단하지 않습니다.
- \(e\) : 단계 6-a로부터 \(e\)가 \( \mathcal{U} \)를 횡단하는 간선 중 가장 작은 비용을 갖는 간선임을 곧장 알 수 있습니다.
그러므로 절단 성질을 적용하면, \(S + e\)를 포함하는 어떤 MST \(T'\)의 존재성을 보장할 수 있습니다. 단계 6-b에서는 \(T\)를 \(T'\)으로, 단계 6-e에서는 \(S\)를 \(S + e\)로 갱신합니다. 그러므로 이번에 단계 6을 끝낸 후에도 정리의 명제가 성립합니다. ■
이제 프림의 알고리즘의 정확성을 증명할 수 있습니다.
정리 9. 프림의 알고리즘의 정확성
알고리즘 4는 올바르게 동작한다. 다시 말해, 어떤 MST를 반드시 출력한다.
[증명] 먼저 알고리즘이 어떤 연결된 부분 그래프를 출력함을 보이겠습니다. 정리 8의 증명에서 논의한 바와 같이 간단한 귀납법을 통해서 우리는 \( R \)이 \(r\)로부터 \(S\)를 사용하여 도달 가능한 정점들의 집합임을 보일 수 있습니다. 만약 알고리즘이 연결된 부분 그래프를 출력하지 않았다면, 분명 어느 순간 단계 6-a에서 \(R\), \(V \setminus R\) 모두 공집합이 아닌데 \(R\)에서 \(V \setminus R\)로 향하는 간선이 존재하지 않았다는 의미입니다. 이는 입력 그래프가 연결되어 있다는 가정에 모순입니다. 정리 8에서 우리는 알고리즘의 최종 출력 \(S\)가 결국 어떤 MST \(T\)의 부분집합이라는 것을 유도할 수 있습니다. 위 사실을 모두 만족시키는 방법은 \(S = T\)밖에 없습니다. ■
마치며
이번 글에서는 MST가 만족하는 흥미로운 특징인 절단 성질에 대해서 공부하고 이를 활용하여 잘 알려진 MST 알고리즘인 크루스칼의 알고리즘과 프림의 알고리즘을 각각 증명해 보았습니다. 특히 절단 성질은 중복된 비용이 있는 경우에도 동작하는 아주 강력한 성질입니다.예전에 보루프카의 알고리즘(Borůvka's Algorithm)에 관한 글을 적었었는데, 그때는 분석할 때 비용이 서로 다르다고 가정했었습니다. 그러면 그래프의 MST는 유일하기 때문입니다. 하지만 절단 성질을 사용한다면 해당 가정이 없어도 보루프카의 알고리즘을 증명할 수 있지 않을까 생각합니다.
이 글을 적으면서 스스로 복습하겠다는 마음이 전혀 없었던 것은 아닙니다. 실제로 본문을 적을 때 교과서를 참고하지 않고 예전에 공부했던 내용을 상기해 가면서, 약간씩 막힐 때는 스스로 직접 증명해 가면서 적었기 때문입니다. 하지만 그 이유보다는 MST를 공부하시는 분들에게 도움이 되고 싶은 마음이 더 컸다고 생각합니다. 수업 시간에 MST 알고리즘의 증명을 배우지 않는다면, 이 글을 통해서 증명은 어떤 식으로 이루어지는지 알아 가셨으면 합니다. 반대로 증명을 다룬다면, 높은 확률로 헤매고 계시리라 생각하는데, 이 글에서 힌트를 얻어 가셨으면 하는 바람입니다.
MST와 관련하여 흥미로운 주제가 조금 더 있습니다. 기회가 되면 포스팅해 보도록 하겠습니다. 읽어주셔서 고맙습니다.
'조합론적 최적화 > Minimum spanning tree' 카테고리의 다른 글
| 보루프카 알고리즘 (Borůvka's Algorithm) (0) | 2021.01.20 |
|---|
